Whisper AI od OpenAI to zaawansowany model do transkrypcji mowy na tekst, który można wykorzystać w różnych zastosowaniach, takich jak przetwarzanie plików audio i wideo. Wdrażam go w swoim projekcie Saas
Whisper AI uruchamiam na Linuxie.
Krok 1: Aktualizacja pip
Przed rozpoczęciem instalacji warto upewnić się, że Twoje narzędzie do zarządzania pakietami Pythona, pip, jest aktualne.
pip install --upgrade pipKrok 2: Instalacja wirtualnego środowiska Python
Stworzenie wirtualnego środowiska jest kluczowe, aby uniknąć konfliktów zależności między różnymi projektami Pythona i utrzymać czystość Twojego systemowego Pythona.
python -m venv whisper-env
source whisper-env/bin/activateKrok 3: Instalacja Whisper
Instalacja Whisper w aktywowanym wirtualnym środowisku jest prostym krokiem, który pozwala na ładowanie i użycie modelu w Pythonie.
pip install git+https://github.com/openai/whisper.gitAlternatywnie, możesz zainstalować stabilną wersję z PyPI:
pip install openai-whisperKrok 4: Instalacja ffmpeg
ffmpeg jest niezbędny do przetwarzania plików audio i wideo. Whisper korzysta z ffmpeg do ładowania i przetwarzania plików audio z plików wideo. Bez ffmpeg, Whisper nie będzie w stanie przetwarzać większości formatów plików multimedialnych.
sudo apt update
sudo apt install ffmpegKrok 5: Instalacja PyTorch
Jeśli PyTorch nie został zainstalowany automatycznie, zainstaluj go ręcznie:
pip install torchKrok 6: Pobranie pliku audio lub wideo
Do przykładu użyjemy filmu z YouTube:
Link: Elon Exposes This Tesla Employee Who Leaked Confidential Data
Instalacja yt-dlp
pip install yt-dlpPobranie filmu:
yt-dlp https://www.youtube.com/shorts/1Z_sEtFNp2A -o "sample_video.mp4"Krok 7: Tworzenie skryptu do transkrypcji
Skrypt Pythona jest używany do załadowania modelu Whisper i przekazania mu pliku audio lub wideo do transkrypcji.
Do przykładu użyłem short-a https://www.youtube.com/shorts/1Z_sEtFNp2A
import whisper
import time
def transcribe(audio_path):
model = whisper.load_model("base")
print("Model loaded. Starting transcription...")
start_time = time.time()
result = model.transcribe(audio_path)
print(f"Transcription completed in {time.time() - start_time:.2f} seconds.")
print(result["text"])
if __name__ == "__main__":
audio_path = "sample_video.mp4"
transcribe(audio_path)
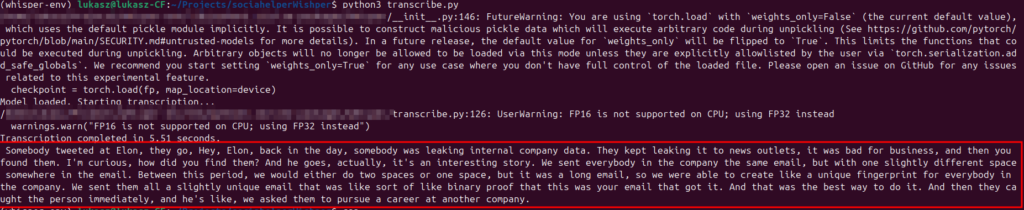
Krok 8: Uruchomienie skryptu i diagnoza błędów
python3 transcribe.pyKrok 9: Wynik